






Yanny or Laurel? A Perspective From the Science of Mind and Brain
I really like the Yanny versus Laurel meme, which exploded yesterday. It helps illustrate some key points about human perception:
- In some situations people can differ wildly in their experience of low-level perception.
- Active top-down expectations (and other, weirder processes) have a strong effect on low-level perception.
So basically, it’s an auditory version of #ThatDress.
Those two points are the TL;DR take-home messages.
There is also a sort of sociological phenomenon worth pointing out: a subset of people responding to this meme seem to have completely missed the point. These folks seem to think that there is some ground truth that can be established solely with the help of audio analysis tools — they then conclude that the whole kerfuffle is a pointless distraction. In 2015 when The Dress went viral, I imagine these sorts of people felt relieved when the ‘actual’ colors of the dress were established. (For some reason I imagine our incurious cynic wanting such debates to end so they can “get back to work” — which for them consists largely of cruising social media for new things to sneer at. )
Lend me your ears
Before I go into what the cynics are missing, let’s just establish what exactly we are talking about here. Here’s the audio file that is causing all the confusion and debate:
What do you hear?! Yanny or Laurel pic.twitter.com/jvHhCbMc8I
— Cloe Feldman (@CloeCouture) May 15, 2018
So which do you hear? Can you hear the ‘other’ one if you put in some effort? Try playing with the volume, and using different device and speaker combinations.
Now watch this video, in which the frequency profile of the file is altered:
you can hear both when you adjust the bass levels: pic.twitter.com/22boppUJS1
— Earth Vessel Quotes (@earthvessquotes) May 15, 2018
If you can only hear one of the two sounds, did the frequency-meddling help you hear the other one? Here is another frequency-alteration demo that may help you hear Yanny or Laurel or both simultaneously.
Okay, you're not crazy. If you can hear high freqs, you probably hear "yanny", but you *might* hear "laurel". If you can't hear high freqs, you probably hear laurel. Here's what it sounds like without high/low freqs. RT so we can avoid the whole dress situation. #yanny #laurel ? pic.twitter.com/RN71WGyHwe
— Dylan Bennett (@MBoffin) May 16, 2018
Side rant: Wanting to “avoid the whole dress situation” is pure philistinism from the perspective of phenomenology, psychology and neuroscience.)
It seems as if the ‘Yammy’ percept corresponds to the higher frequencies, and the ‘Laurel’ percept corresponds to the lower frequencies. I say ‘seems’ because talking to my friends made me realize that there is more to this.
Anyway, spend a few minutes listening and experimenting before reading further.
Why analyzing the sound file is not sufficient to explain the phenomenon
The cynics who are in a tearing hurry for a ‘solution’ to this ‘debate’ think that the reason the phenomenon is interesting is because people are ‘confused’ about some objective state of affairs — one that can actually be resolved easily with ‘science’ by examining the audio file itself. But audio files are only part of the story — any explanation that leaves out psychophysics and/or neuroscience is going to be missing what is arguably the most interesting aspect of Yanny vs Laurel: the differences among people that show up at the perceptual level.
There is no one-to-one mapping between sound files and auditory percepts. The measurable properties of the sound file are objective, but they do not tell us what a person will hear, let alone what they should hear. If we could do statistics on a large number of people, we could decide which percept, Yanny or Laurel, was more common, but we should be very clear: the people hearing the other percept are no more wrong about their experiences than people for whom coriander tastes like soap.
This means that playing with frequency alteration tools on your digital audio workstation cannot fully account for several crucial observations that multiple people can corroborate:
- Some people can only hear one of the two sounds, even when the frequency is altered.
- Some people can hear both, and can voluntarily shift attention from one to the other.
- Some people initially hear one of the two, and then start to hear the other.
- Some people no longer hear what they initially heard.
- Some people continue to hear what they originally heard, even when the corresponding frequency range is removed (!)
Moreover, changing the original file misses a key point: the perceptual mystery has to do with a particular soundfile and not the altered versions. The same confusion happened with the dress: people modified the original image to “prove” what the accurate percept was. Or worse, they took a new photograph of the dress to show that it was really black and blue. The inability to determine the objective reality of whether the dress was black-and-blue or white-and-gold under normal white light illumination was not the source of the amazement — the amazement stems from the fact the people can disagree in their perception of a given stimulus.
In other words, these memes are interesting because of their ability to produce divergent phenomenal content (or qualia), not their ability to highlight failures to accurately represent some objectively measurable state of affairs in the world. Failures of representation and interpretation are, sadly, far too common to be interesting.
A little phenomenology
Let me describe my experience of this. I was sent the Yanny-Laurel tweet, which I opened on my phone (a Pixel). I played the sound, and could only hear “Yanny” (or something closer to “Yammy”). I couldn’t for the life of me figure out how my friends were hearing “Laurel” — the vowel sounds seemed so different. I couldn’t hear any bass sounds, even when I changed the volume.
Then I saw the first frequency alteration video. I heard “Laurel” when almost all the high frequency content was removed, at the very beginning of the video. I then moved to my laptop, and tried the built-in speakers, external speakers, and a set of headphones. In all three cases, I could only hear “Laurel”, regardless of the volume. Ever more weirdly, I could no longer hear “Yanny” at all in the frequency alteration video. I thought it might have to do with the soundcard, so I went back to the phone. But I could no longer hear “Yanny” through my phone! I felt as though I had lost something!
Then I took a break — my ears didn’t really appreciate all the experimentation. When I tried again after half an hour or so, I was able to hear both “Yanny” and “Laurel”. I can modulate my percept from one to the other slightly, but not that much.
Perhaps something like ‘fatigue’ temporarily reduces my ability to hear “Yanny” — this weakening of my sensitivity to high frequencies could be at an early point in the auditory system, like in the cochlea, or higher up in the network, in auditory cortex or even higher. (For now I can only speculate, but the auditory neuroscience literature may shed light on the issue.)
This morning I came across the second frequency alteration video, which involves a nicely visualized cutting of the spectrogram. I could hear both sounds in the original recording, “Yanny” when the highs were kept, and “Laurel” when the lows were kept. I have friends who say that they can only hear “Laurel” even when all the low frequency content is removed!
A good explanation requires a proper psychophysics experiment
Assuming that no one is lying, these phenomena cannot be explained — or explained away, which is what some people seem to be attempting — with pure sound file analysis. There does not seem to be a stable relationship between the sound file parameters and the percept, which is why the experience can switch over time, even when the same equipment is used.
Clearly a full scientific analysis requires quite a bit of experimentation. Factors that can be manipulated include:
- The sound equipment: sound card, speakers, etc
- The volume of the file
- The envelope of the power spectrum of the frequencies (which creates a new audio file)
- The ambient noise
- The number of times the sound file is played
- The order in which different frequency-modifications are performed
- The prior experience of the listener: were they listening to music? talking? in a noisy room?
- The prior information of the listener: what were they told/shown before listening?
- The listener’s effort and/or attention
- The listener’s mother tongue, cultural and ethnic background, music taste, and so on
A speculative explanation — the magic of top-down processing
I’d like to now offer a speculative explanation of the phenomenon — which as I have stressed, involves individual differences in experience, rather than failures to infer an objectively measurable ground truth. My speculations are informed by neuropsychological models: particularly models of how top-down and bottom-up processes interact.
Bottom-up signals are those that arise as a result of ongoing events in the world (and/or in the body), whereas top-down signals are those that arise as a result of processes in “higher order” parts of the brain, such as memory, planning, decision-making, language, emotion, guesswork and so on. Let’s look at some diagrams of the auditory system to get a sense of what “bottom-up” and “top-down” mean.
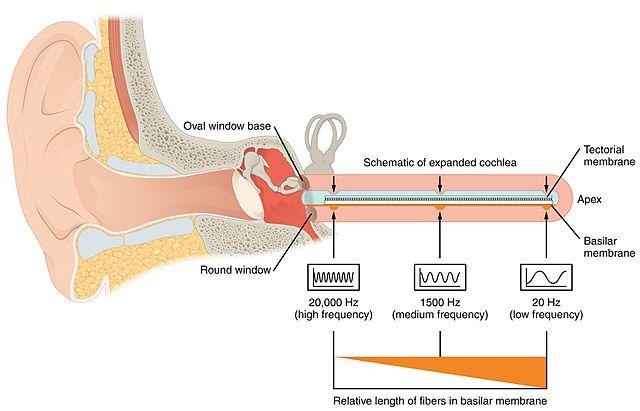
In this schematic diagram, the spiral-shaped cochlea is “unrolled” to show its frequency-selectivity properties. Image source: Wikimedia Commons.
You may recall from school science class that acoustic vibrations in the air reach your ear and then cause the eardrum to oscillate. The eardrum’s oscillations are transmitted, via three tiny bones, to a structure called the cochlea. Vibrations of a structure in the cochlea called the basilar membrane excite neurons, thereby triggering action potentials or “spikes” — the main form in which signals travel in the brain. Many of the neurons are frequency selective, so you can think of the cochlea as doing something vaguely like a Fourier transform (but of course it’s way more complicated than that).
From the cochlea, spikes travel towards the cortex. At some point in this causal chain, hearing occurs. Here’s a schematic diagram of the low-level circuitry:
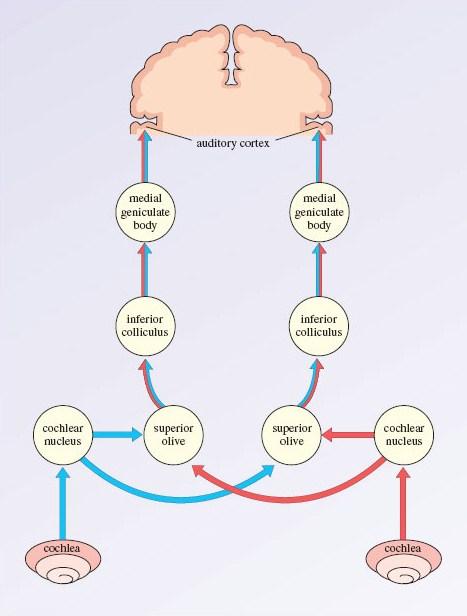
Image Source: The Open University (very good resource!) Note that all neural circuit diagrams leave out details and complexities to make them legible. For example, in this diagram, top-down signals from the auditory cortex back to the medial geniculate body are not shown.
Signals that go from the medial geniculate nucleus (MGN; a part of the thalamus) to the auditory cortex are typically considered “bottom-up” connections, whereas signals that go from the cortex back to MGN are considered “top-down” connections.
Top-down and bottom-up are relative notions. For any given brain area, we can often categorize its inputs as either top-down or bottom-up. The primary auditory cortex sends bottom-up signals to association cortices, and the association cortices signals send top-down signals back to primary auditory cortex.
Let’s imagine a cartoonishly simplified auditory circuit that consists of two neuronal layers: a ‘frequency map’ containing neurons that respond to particular sound frequencies, and a ‘pattern map’ containing neurons that respond to particular combinations of frequencies. The frequency map sends bottom-up signals to the pattern map, and the pattern map sends top-down signals to the frequency map. We’ll throw in some inhibition in the pattern map, which can mediate competition between different patterns.
Here’s a diagram of the circuit:
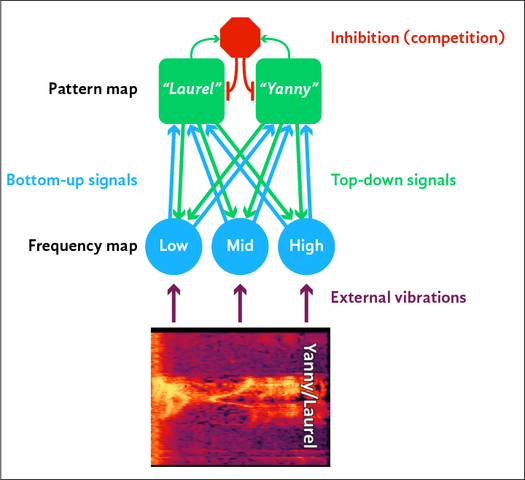
Here the pattern map is ‘balanced’, which may resemble what is happening in people who can hear both “Yanny” and “Laurel” simultaneously.
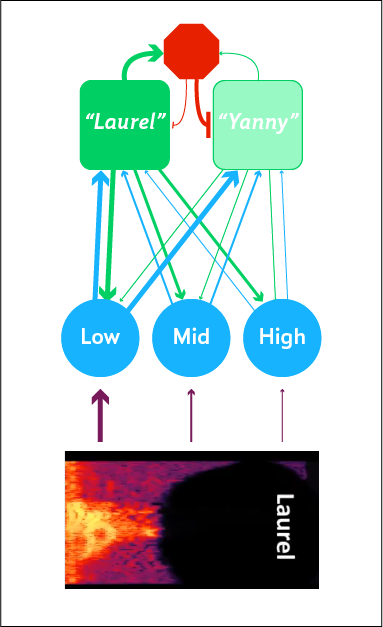
Something like the following seems to happen when the high frequencies are removed, allowing “Laurel” to be heard (at least by some people):
Things are flipped around when the low end is removed, so “Yanny” becomes more perceivable:
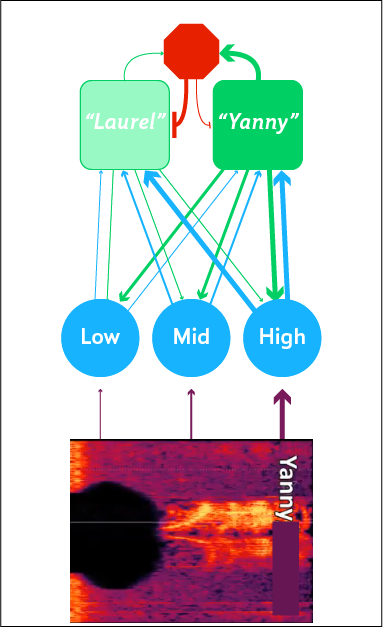
Now that we have a toy model to guide our thinking, we can think mechanisticallyabout the neural bases of individual differences.
Why might some people tend to hear “Laurel”, and others hear “Yanny”, when the signal arriving at their ears is roughly the same? (Let’s assume they are in the same room listening to the same speakers.) One possibility is that their is some intrinsic bias in their auditory network. It may occur at the frequency map level: some people’s low level bottom-up sensitivities may be skewed towards the low end or the high end of the frequency spectrum.
Another possibility is that the bias is at the pattern map level: some people’s pattern maps may strongly weight one end of the spectrum or the other. Such biases may translate into top-down signals that amplify activity in the frequency map, creating a reinforcing feedback loop in which the top-down expectation strengthens the expected signal.
Extreme top-down excitation might be one explanation for hallucinations. And a milder version may account for why some people continue to hear “Laurel” even when there is no low-frequency content in the external sound. One possible way for this to happen is illustrated below:
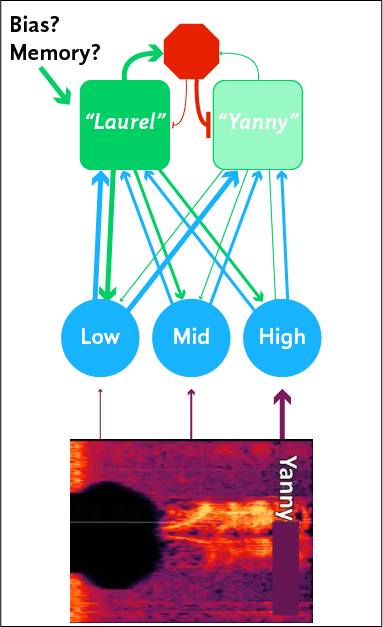
Not how the top-down signaling enables a “filling-in” of the low-frequency information that isn’t actually present in the external signal.
These static diagrams can only convey so much. They don’t give us an obvious way to represent time- or exposure-dependent phenomena such the ‘fatigue’ effect. In my case, perhaps the cells in my frequency map that convey high-frequency signals get “tired”, and stop firing strongly after a while. This could allow the low-frequency signals to “pop out” relative to before, and allow “Laurel” to win the competition that it was losing earlier. (There are of course other ways of imagining the same fatigue effect, even in this toy circuit. Try to think of at least one!)
I want to stress that the circuit model I have walked you through is speculative — toy models like this are a way to at least start thinking about the issues at play. It doesn’t count as a full-fledged explanation, which, as I mentioned before, requires much more data as well as theory and computational modeling.
Ideally, a theoretician will start with a very simple model like this, and then add “infrastructure” as needed to incorporate more and more aspects of the phenomenon, both on the psychological level, and at the neurobiological level. Additional mechanisms will most likely need to be added to account for the effects of attention, memory, language, culture and other “higher order” processes. And the circuit model will need to be much more fleshed out if it is to be compared to the actual auditory system.
For those who have made it this far, I should also point out that certain philosophical assumptions are implicit even in a toy model like this. One assumption is that top-down excitation of some part of the brain can in principle produce a subjective percept that is indistinguishable from the experience of an external signal. There is a lot of data to back up this assumption, but ultimately science never directly measures subjective experience, which is why a philosopher might raise all kinds of objections.
Further assumptions arise when we make the model more neurobiologically specific. If I claim that the frequency map is in primary auditory cortex, I might be committing to the idea that the subjective experience of sound requires activation here. But it may be that activation at some other point in the circuit may also work just fine. Moreover, it may be that certain properties of overall brain dynamics determine whether some local activation produces subjective qualia.
Circuit models of the sort I’ve illustrated here rarely account for all the aspects of a perceptual phenomenon — computational neuroscience is still very much in its infancy. But I hope that by constructing a toy model I have helped draw people’s attention to the various facets of the phenomenon underlying the Yanny/Laurel meme, and related ones like the Dress. In particular, I want to raise people’s awareness of top-down processing, which cannot be studied by playing with bandpass filters in a digital audio workstation.
Rather than trying to avoid situations like the Dress, people should look for them and pay attention to them, since they offer little windows into the mystery that is human consciousness. And you may even come across a phenomenon that cognitive scientists and neuroscientists haven’t discovered yet!
Further reading
If you are as fascinated by the Laurel/Yanny thing as I am, you will most likely enjoy looking into the world of auditory illusions and other oddities from the word of psychophysics. Check these out:
Several researchers frame psychophysical phenomena in terms of top-down and bottom-up interaction, but it my opinion the person who has explored the issue most deeply is Stephen Grossberg. Full disclosure: I did my PhD in the department he founded, so I took courses that taught his models (which are not as widely known in neuroscience and cog sci as they should be). He was not my thesis advisor though.
People with a computational background might benefit from exploring Grossberg’s Adaptive Resonance Theory. He defines “resonance” as a kind of agreement between top-down expectation and bottom-up “reality”.
One of my friends worked with Grossberg on a computational model of phonemic restoration:
Grossberg, S., & Kazerounian, S. (2011). Laminar cortical dynamics of conscious speech perception: Neural model of phonemic restoration using subsequent context in noise. The Journal of the Acoustical Society of America, 130(1), 440-460.
(Yohan John is a neuroscientist at Boston University)
Get the latest reports & analysis with people's perspective on Protests, movements & deep analytical videos, discussions of the current affairs in your Telegram app. Subscribe to NewsClick's Telegram channel & get Real-Time updates on stories, as they get published on our website.















